
 3e Project: Model evaluation & validation
3e Project: Model evaluation & validation
Project details
DESCRIPTION:
- use Boston house price dataset to PREDICT selling price of a new/unseen home
PROCESS:
- EXPLORE data > obtain important FEATURES & DESCRIPTIVE statistics abt data
- Properly SPLIT dataset into TRAINING & TEST datasets
- DETERMINE suitable PERFORMANCE METRIC for evaluating the problem
- ANALYSE performance graphs for learning algorithm over varying TRAINING SET SIZES & with varying number of PARAMETERS
- CHOOSE OPTIMAL MODEL that best generalises unseen data
- TEST chosen optimal model on a NEW SAMPLE & COMPARE PREDICTED selling price to ACTUAL statistics
PURPOSE:
- gain familiarity working with data in Python, & applying basic ML algorithms using NumPy & SKLEarn
- practice building models & analysing/interpreting their performance
LEARNING OUTCOMES:
- using NumPy to INVESTIGATE dataset’s FEATURES
- analysing various LEARNING CURVE plots/performance for VARIANCE & BIAS
- determining best-guess MODELS for PREDICTION of unseen data
- evaluating MODEL PERFORMANCE on unseen data using previous data
SOFTWARE REQS:
- Python 2.7
- NumPy
- Pandas
- SciKitLearn v 0.17
- MatPlotLib
- Jupyter Notebook
KEY POINTS:
- AIM of ALGORITHM is to OPTMISE SELLING PRICE > hence more important NOT to UNDERPREDICT PRICE than it is to over-predict
FILES:
- boston_housing folder in Udacity GitHub repo
- filenames: boston_housing.ipynb; housing.csv; visuals.py
- additional info files: README; project_description.md
HOW TO USE:
- Download files from GitHub
- At Command Prompt navigate to folder containing project files
- Open browser window to work on Notebook using: jupyter notebook boston_housing.ipynb
- Alternatively, open Notebook using: jupyter notebook then navigate to folder to open relevant Notebook file
- Follow instructions in Notebook; see also README file
MY INSTRUCTIONS FOR DOWNLOADING from GitHub onto local machine:
- FORK udacity’s GitHub machine-learning repo
- CLONE my fork of repo into DIRECTORY in ~\Desktop\MLND\
- Note: don’t need to set up sub-directory for repo (ie called machine-learning), git will set one up when cloning
- Instructions for cloning a repo are here: https://help.github.com/articles/cloning-a-repository/
- If wrongly set-up (wrong place, name, etc), directory can be changed or moved using: move “{incorrect filepath}” {correct filepath} [eg move “C:\Documents and Setings\$USER\project” C:\project] OR just move in File Explorer as normal >> safest is to (a) DELETE wrongly cloned directory; (b) RECLONE to correct path
Project workings
MY INSTRUCTIONS FOR STARTING PROJECT in Jupyter Notebook:
- Starting Project:
- In Command Prompt navigate to C:\Python27\Scripts\~ (this is where Jupyter has been installed to) and type:
- jupyter notebook
- This opens the Jupyter Notebook in a web browser; it takes a while to open so be patient!
- Note: CMD will continue to run in background; this is fine, don’t close CMD down!
- Uploading the required file if not already available (first time only):
- Click on UPLOAD button in top right
- In file browser, navigate to .ipynb file (on your local machine > see notes above for how to download repo from GitHub to local) you wish to open [eg from directory Dekstop\MLND\machine-learning\projects\boston_housing\, open file boston_housing.ipynb]
- Highlight file & click on OPEN
- Chosen notebook file appears in list of files on LHS. Click on UPLOAD button at RHS to confim
- The notebook file has now been added to the list of available files to browse
- Single-click on the filename to open the Notebook – opens in a new tab in the web browser
- You can now view/edit/etc this Notebook
- In Command Prompt navigate to C:\Python27\Scripts\~ (this is where Jupyter has been installed to) and type:
- Running Project Code in Jupyter Notebooks:
- Need to UPLOAD file visuals.py from local machine into the Jupyter Notebooks browser session in order for the Code to execute properly (otherwise returns error msg: “ImportError: No module named visuals”)
- Ditto CSV data file (housing.csv) > error msg: “File housing.csv does not exist”
- Place cursor in box of code to be executed & either press Control+Enter or hit the Execute Code button
- Code & comments can be added/amended/deleted as in a normal Python program
- On execution, any print statements will return results in the space below the box of code
- Adding/Editing Answers in Markdown:
- Click on section to be edited so it’s highlighted, then double-click to enter that section
- Add/edit as required; a useful cheat sheet on using Markdown is available here: https://github.com/adam-p/markdown-here/wiki/Markdown-Cheatsheet
- While cursor is still inside box (so it’s highlighted/active), click the Execute button to accept the Markdown edits & display them as normal text
- Saving & Closing Project:
- Be sure to periodically save Notebook using the Save & Checkpoint button
- NOTE: To close down current running Notebook, Save & Checkpoint the session, then choose Close & Halt from the menu. This will close the Notebook session, stop it running & close the browser tab. Go to that filename in the list on the Menu tab (which will still be open) & check that it shows the Notebook is no longer running. If it did currently show it as still running, click the box then select the SHUTDOWN option
- NOTE: To close out of Jupyter Notebook all together, close the web browser (or all relevant Jupyter Notebook tabs). Then, at Command Prompt session, enter Cntrl+C (interrupt) to shut down. (It will show a confirmation msg that kernel has been closed. Type exit to close CMD completely.) There is currently no ‘safer’ way to shut down the Jupyter kernel; this is what everyone does.
Dataset
Original dataset available from: https://archive.ics.uci.edu/ml/datasets/Housing
data (cleaned DATASET – outliers & erroneous datapoints removed) = 489 data rows, 4 columns:
- RM: av no. of rooms in homes in the neighbourhood
- LSTAT: % of homeowners in neighbourhood considered ‘lower class’ (working poor)
- PTRATIO: ration of students to teachers in primary & secondary schools in neighbourhood
- MEDV: house prices (scaled to account for inflation)
Split into 2 datasets:
- features (FEATURES) = RM, LSTAT, PTRATIO
- prices (TARGET VARIABLE ie LABELS) = MEDV
Check & print out shape of dataset using:
print “Boston housing dataset has {} data points with {} variables each.”.format(*data.shape)
Returns:
Boston housing dataset has 489 data points with 4 variables each.
Implementation – Calculate Descriptive Statistics
REQUIRED: Calculate minimum, maximum, mean, median, and standard deviation of MEDV, which is stored in prices & store each calculation in their respective variable
Calculate using:
- min_price = min(prices)
- max_price = max(prices)
- mean_price = np.mean(prices) # after importing NumPy using: import numpy as np
- median_price = np.median(prices)
- std_price = np.std(prices, ddof=1)
Note: np.std(array) without further arguments gives std devn of POPULATION; whereas using np.std(array, ddof=1) returns std devn of SAMPLE, with ddof=1 indicating no. of degrees of freedom to be used in caln of std devn
Print out calculated statistics formatted to 2 dp using (eg):
print “Standard deviation of prices: ${:,.2f}”.format(std_price)
Returns:
Minimum price: $105,000.00
Maximum price: $1,024,800.00
Mean price: $454,342.94
Median price $438,900.00
Standard deviation of prices: $165,340.28
Question 1 – Feature Observation
How wld I expect movement in value of Features to effect Price (intuitively)?
- As RM value (av # of rooms) increases MEDV value (price) can be expected to increase, since higher RM value indicates more rooms in houses in the area, indicating larger houses which are likely to be higher price;
- As LSTAT (% of homeowners in neighbourhood considered ‘lower class’) increases MEDV (price) can be expected to decrease, since less affluent homeowners are likely to reside in areas where house prices are lower, hence more affordable;
- As PTRATIO (student-teacher ratio) increases (i.e. more student per teacher or larger class sizes) MEDV (price) might be expected to decrease, since higher class sizes implies a lower quality of schooling in the area while better quality schools (as suggested by lower class sizes) tends to push up house prices*.
*This tendency is true in UK (particularly suburban areas), although this may be a localised effect which is not applicable to Boston or USA.
Implementation – Define a Performance Metric
Given Metric = Coefficient of Determination R^2 (R-squared) (documentation here)
R^2 scores between 0 (model does not generalise & cannot predict new results for unseen data) to 1 (model generalises well & perfectly predicts new results from unseen data). Values in between 0 & 1 indicate that decimal value (as %) of results can be accurately/correctly predicted for unseen data (eg R^2=0.1; 10% accurately predictable; R^2=0.7; 70% accurately predictable)
Specifically R^2=0 indicates model’s predictions are no better/no more accurate than a model which always predicted the mean of the data
Potentially R^2<0, which indicates the model is arbitrarily worse than a model which always predicted the mean
CODE:
- Use r2_score from sklearn.metrics to perform a performance calculation between y_true and y_predict
- Import ‘r2_score’ function using: from sklearn.metrics import r2_score
- SKLearn documentation available here (see Section 3.3.4.5.) and here
- Define a function to take data inputs of actual and predicted values, assign a performance score to a variable called score, and return the variable:
def performance_metric(y_true, y_predict):
____score = r2_score(y_true, y_predict)
____return score
To calculate the score for given data variables, call the defined function using: score = performance_metric(y_true,y_predict). Alternatively, pass arrays directly into the function, eg: score = performance_metric([3, -0.5, 2, 7, 4.2], [2.5, 0.0, 2.1, 7.8, 5.3]) which returns an R2 of 0.923.
ANALYSIS – Goodness of Fit (example):
BEFORE calculating R^2: From a cursory review of the predicted and actual values in the table, we can see that the absolute variance between prediction and actual is small in most cases: (0.5, 0.5, 0.1, 0.8, 1.1). This gives a mean sum of squares error score of 0.6 indicating a low error rate.
However, I would caveat this answer by noting that: (i) the sample size is very small so may not be representative of a wider population, and (ii) without more description/narrative about the data points it is difficult to draw binding conclusions.
AFTER calculating R^2: The R^2 calculated at 0.92 which confirms my above view that the predictions show high accruacy (1.0 being perfect accuracy). Hence the prediction model which returned these results would be expected to generalise well to unseen data.
Implementation – Shuffle & Slit the Data
The two datasets (features, prices) are each split into testing and training datasets using SKLearn’s cross-validation function as before:
from sklearn import cross_validation
X_train, X_test, y_train, y_test = cross_validation.train_test_split(
____features, prices, test_size=0.2, random_state=25)
print X_train.shape, y_train.shape
print X_test.shape, y_test.shape
print X_test
The random_state=10 randomises the data samples before splitting, but ensures consistency of randomisation across both train and test sets (note: this can be any integer value). The print commands are used to check the results look correct
Question 3 – Training & Testing
Why split the data into training & testing datasets?
The benefit of splitting a dataset into training and test datasets when using a learning algorithm is to provide data sufficient to allow the algorithm to learn on (training data) but with some independent data held back in order to test the learning algorithm for accuracy and goodness of fit. This ensures the algorithm is performing optimally before applying it to new unseen data.
If we simply ran the learning algorithm against all of the available sample data without performing this independent validation process, there is a danger of algorithm overfitting, that is perfectly fit the sample but be unable to generalise to the general population.
Execution – Learning Curves
We can produce Learning Curves on our original dataset (split into FEATURES and LABELS) to establish the algorithm’s accuracy score (here, R^2 score) when applied to different sizes of training dataset and for other model parameters (here, depth in a Decision Tree Regression algorithm). Plotting such learning curves and comparing scores between training and testing Learning Curves allows us to infer the optimal learning model parameters and training dataset size to use in order to minimise both bias and overfitting errors.

Question 4 – Learning the Data
Analysis one example graph only:
Looking at the model with maximum depth of 10, the training curve can be seen to be very flat and at a very high accuracy score of almost 1 (near perfect accuracy). This pattern is observed regardless of the number of training datapoints added. Similarly the test curve shows a relatively flat curve but at a much lower accruacy score, never exceeding c. 70% accuracy despite the addition more test datapoints. The two curves never converge.
This is a classis graph of an overly complex model which overfits to the training data but, despite adding more training datapoints, will never be able to generalise to the independent test dataset which scores a consitently low accuracy score.
Analysing all graphs (not required):
The bottom two plots show instances of the algorithm overfitting the training data due to model complexity (depth = 10 or 8). Here the training curve remains very high at near 1 (almost perfect accuracy) regardless of size of the training dataset, with this pattern being particularly pronounced in the case where max_depth=10. Adding more training data points does not change this pattern. When this learning algorithm is validated against the test dataset, in both cases the test curves do not converge with the training curves, despite adding more datapoints, which is a classic size of overfitting due to model complexity and shows the model is not generalising well to unseen data. This pattern is especially pronounced in the model with a maximum depth of 10.
The first model (where maximum depth is 1) shows convergence of training and test curves, but here the accuracy score is very low at around 0.4. This indicates a bias error in the model, due to the model being too simple, i.e. it is not able to well represent the underlying complexity in the data. Here, no mater how much additional training data is added, the model will always return a low accuracy score.
The second model (top right), which has a maximum depth of 3, shows good convergence between the training and test curves, indicating that the model is generalising well to unseen data (does not suffer from overfitting). This convergence takes place at a relatively high R^2 score of c. 0.8, or 80% accuracy, indicating the model is sufficiently complex to represent the underlying data relationships (does not suffer from bias). This model’s learning curves suggests an optimal model of maximum depth 3 and training dataset size of around 300 datapoints.
Execution – Complexity Curves
We can now apply the same learning curve metric on the split data (training and test datasets) for a variety of model complexities, and comparing the plotted results. This allows us to evaluate the model complexity and establish the optimal maximum depth.
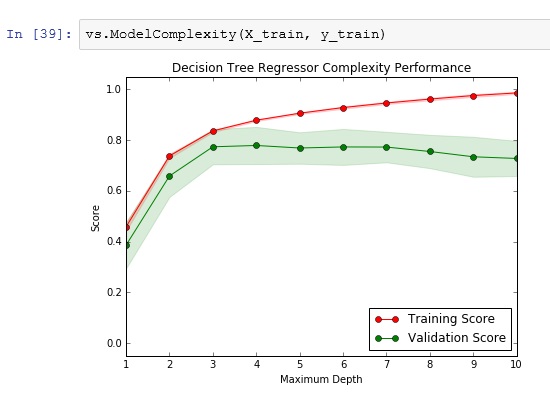
Question 5 – Bias-Variance Tradeoff
Training the model at a maximum depth of 1 results in well-converged training and test scores, but the learner’s performance (R^2 score) on the training set is very low at c. 0.4, or 40% accuracy. This indicates the model is over-simplified and suffers from bias or underfitting.
When the model is trained at a maximum depth of 10, there is a large divergence between the training and test scores. Here, despite good performance on the training set (R^2 near 1), the test set is not performing well and has a much higher error rate. This indicates the model at this depth is not generalising well to the unseen test data, and is suffering from high variance or overfitting.
Question 6 – Best Guess Optimal Model
From the graph it appears the model which maximises performance (highest R^2 score) and generalises best to unseen data is with a maximum depth of 3. This is because, at max_depth = 3, the training and test curves are converged (minimal gaps indicate the model is generalising well to the test data), and also this model is sufficiently complex to reduce the errors seen where max_depth was 1 or 2 (as evidenced by the higher R^2 score). This is also confirmed by the R^2 score on the test complexity curve tailing off where max_depth > 3.
Question 7 – Grid Search
Grid Search is a validation technique for model optimisation which provides a visual tool to allow identification of bias and variance errors and find optimal parameters for the learning algorithm (training size and model complexity). The technique plots a 3-dimensional complexity graph in an xyz-space, which represents a series of learning curves (training size V learning curve score, xy) for various model complexities (z-axis). From this plot, one can see visually how model complexity improves (or not) the learning algorithm’s performance.
Question 8 – Cross-Validation
The k-fold cross-validation technique is a method where the sample dataset is split randomly into k number of buckets or ‘folds’. These k folds are then split into training and test sets, with (k-1) folds becoming the training data for learning, while the final kth fold acting as test data for model validation. The learning algorithm cycles through the training-test splits k times so that all datapoints act as both training data and test data at some point in the cycle, and takes the average of all results from all k learning cycles.
Grid search and other cross-validation techniques require randomisation of the data before splitting into training and test sets to remove any problems arising from ordered data. But, depending on which random data split (training v test) we use, different results are obtained each time because each unique training/test split provides a slightly different set of training data on which the algorithm will learn. As a result, we can’t be sure we’ve got the most reliable results for any given train-test split, while outliers in the data may be more likely to skew results.
The k-fold cross-validation technique overcomes this problem by cycling through the k folds of data, using all data points for both training and testing, and taking an average overall result. This leads to learning which is more accurate and avoids the possibility of rogue datapoints skewing the results.
Implementation – Fitting a Model
To implement a grid search on a Decision Tree learning algorithm using the ShuffleSplit function (a cross-validation technique similar to the k-fold cross-validation above):
- Cross-Validation (ShuffleSplit):
- Documentation available here
- ShuffleSplit function is available within cross-validation package which is imported using: from sklearn import cross_validation
- Create a ShuffleSplit object assigned to a variable called cv_sets using: cv_sets = ShuffleSplit(X.shape[0], n_splits = 10, test_size = 0.20, random_state = 0)
- The ShuffleSplit function creates n shuffled splits (denoted by parameter n_splits); in this example n_splits=10 and each shuffle is split into 80% training & 20% test data
- Decision Tree Regressor:
- Documentation available here
- Simple form: DecisionTreeRegressor(max_depth=n)
- max_depth indicates depth to which decision tree will operate, ie maximum number of questions it will process; default is None
- Import function using: from sklearn.tree import DecisionTreeRegressor
- Create decision tree regressor object assigned to a variable called regressor using: regressor = DecisionTreeRegressor()
- Note: it is not necessary at this stage to indicate max_depth parameter for this function, as this will be done later in the code by passing a value from params dictionary (see next step) into the function
- Documentation available here
- Maximum Depth:
- To cycle through model complexity, denoted by maximum depth parameter called max_depth (key), set up a dictionary called params containing range of values from 1 to 10 (values) using: params = { ‘max_depth’: range(1,11) }
- Note: the dictionary is a tuple or key/value pair; here the key is the string ‘Max_depth’ and the value is a list of integers 1-10. This key/value pair (where key is a string and value is a list) will later be passed into the Grid Search function so needs to be in this form
- Scorer:
- Documentation available here
- Simple form: make_scorer(score_func)
- score_func is the scoring function to be passed to the scorer
- default assumes score_func is a scoring function (high=good), rather than a loss function (low=good)
- Import function using: from sklearn.metrics import make_scorer
- Create an object to score the model, and pass result of performance_metric function to it, using: scoring_fnc = make_scorer(performance_metric)
- Note: the performance_metric function was defined earlier (see above), and takes the algorithm’s y_true and y_predict values and calculates the R^2 score
- Documentation available here
- Grid Search:
- Documentation available here
- Full form: GridSearchCV(estimator, param_grid, scoring=None, fit_params=None, n_jobs=1, iid=True, refit=True, cv=None, verbose=0, pre_dispatch=’2*n_jobs’, error_score=’raise’)
- Simple form: GridSearchCV(estimator, param_grid, scoring={name of scoring function}, cv={name of cross-validation })
- estimator is the fitting function, in this case the decision tree regressor called regressor
- param_grid sets up the various parameters the Grid Search is to apply across, and takes the form of a dictionary whose key is the parameters name (string) and whose value is a list of parameter settings to apply; in this case the param_grid is the dictionary called params
- scoring is the callable scoring function, in this case the make_score function called scoring_fnc; note: the scoring function must take the form scorer(estimator, X, y), in this case it’s form is make_scorer(performance_metric) where performance_metric is the callable function as described above
- cv is the cross-validation generator, in this case the ShuffleSplit function called cv_sets
- Import function using: from sklearn import grid_search
- Create a grid search object, taking variables regressor, params, scoring_fnc and cv_sets and assigning result to a variable called grid, using: grid = GridSearchCV(regressor, params, scoring=scoring_fnc, cv=cv_sets)
- The sample data can then be fitted to the Grid Search using: grid = grid.fit(X, y)
- Documentation available here
Note: in this example the grid search function is defined as a callable function called fit_model, which takes arguments for features and labels datasets and returns the optimal model after fitting the data. The function definition takes the form:
def fit_model(X, y):
____... function as above description ...
____return grid.best_estimator_
This data-fitting function is then called on the training data (X_train, y_train) to fit the training data to the model with grid search, using: reg = fit_model(X_train, y_train)
Problems & Resolutions
1. Problem with initialising ShuffleSplit as couldn’t identify n_splits: solved by changing to n_iter = 10 (n_splits is used in v0.18 of SKLearn, I am using v0.17)
2. Couldn’t recognise global ‘GridSearchCV’: resolved by importing it from grid_search using: from sklearn.grid_search import GridSearchCV
3. AttributeError: ‘ShuffleSplit’ object has no attribute ‘items’: One forum post suggests it’s cause by params dictionary containing a list where it should be integers but I confirmed the dictionary params is in the correct form. Another forum post (https://discussions.udacity.com/t/project-1-attributeerror-shufflesplit-object-has-no-attribute-items/201319) offers solution: when passing variables to the GridSearchCV function, it is necessary to specify parameter names otherwise the function tries to pass variables into different parameters than the ones intended. Fixed by using: grid = GridSearchCV(regressor, params, scoring=scoring_fnc, cv=cv_sets)
Correcting these errors allows the code to work successfully!
Question 9 – Optimal Model
Running the code using reg = fit_model(X_train, y_train) fits the training data to the model with grid search and returns the optimised model to the variable called reg. To print out and review, use: print reg. This gives, eg:
DecisionTreeRegressor(criterion=’mse’, max_depth=4, max_features=None,
____max_leaf_nodes=None, min_samples_leaf=1, min_samples_split=2,
____min_weight_fraction_leaf=0.0, presort=False, random_state=None,
____splitter=’best’)
The maximum depth parameter (max_depth) for the optimal model can be retrieved using: reg.get_params()[‘max_depth’]. Other parameters may be accessed using the same construct.
To output the required parameter in pretty print, use: print “Parameter ‘max_depth’ is {} for the optimal model.”.format(reg.get_params()[‘max_depth’])
The Grid Search method applied to the decision tree regressor calculates a maximum depth of 4 (sometimes 5 or 6) to optimise the model. This is higher than I suggested in Question 6 when viewing the complexity graph by eye.
Important Point
GridSearch is splitting up the Training Data into two sets, one for training & one for validating (to allow for fine-tuning of the model). This optimised model can then be tested against the Test set which has been held to one side. See this forum post for more info.
Project predictions: Boston housing prices
Question 10 – Predicting Selling Prices
The trained and optimised model may now be used to predict results on unseen data. A real world example for the house prices data is an estate agent using the model to predict expected selling price (MEDV) of 3 new homes, given their features (below), in order to best advise their clients how to maximise their homes’ selling prices:
________________________________________Client 1____Client 2____Client 3
- RM: no. of rooms in the home_________________5________4________8
- LSTAT: neighbourhood poverty level (%)_________17_______32________3
- PTRATIO: student-teacher ratio of nearby schools__15:1______22:1_______12:1
To run the prediction model, first set up data matrix for new data:
client_data = [[5, 17, 15], # Client 1
_______________[4, 32, 22], # Client 2
_______________[8, 3, 12]] # Client 3
Then iterate through items in the new data matrix to predict results based on the optimised model (reg) using:
for i, price in enumerate(reg.predict(client_data)):
____print "Predicted selling price for Client {}'s home: ${:,.2f}".format(i+1, price)
Running the prediction model gives the following predicted selling prices:
Client 1’s home: $409,395.00
Client 2’s home: $195,416.67
Client 3’s home: $950,425.00
Requirement:
Indicate whether the predicted prices seem reasonable given the 3 homes’ features (answered in relation to descriptive statistics calculated earlier + my intuitive expectations in Qu.1)
My intuitive expectations regarding prices given different features (Qu.1):
- As RM value (av # of rooms) increases MEDV value (price) can be expected to increase, since higher RM value indicates more rooms in houses in the area, indicating larger houses which are likely to be higher price;
- As LSTAT (% of homeowners in neighbourhood considered ‘lower class’) increases MEDV (price) can be expected to decrease, since less affluent homeowners are likely to reside in areas where house prices are lower, hence more affordable;
- As PTRATIO (student-teacher ratio) increases (i.e. more student per teacher or larger class sizes) MEDV (price) might be expected to decrease, since higher class sizes implies a lower quality of schooling in the area while better quality schools (as suggested by lower class sizes) tends to push up house prices*.
Process:
In addition to the price stats I also calculate stats for the features in the sample dataset as well, as follows:
print "Descriptive Statistics: min/max/mean/median (to 1 d.p.)"
for feature in features:
____min_f = min(data[feature])
____max_f = max(data[feature])
____mean_f = np.mean(data[feature])
____median_f = np.median(data[feature])
____print feature, ": {:,.1f} {:,.1f} {:,.1f} {:,.1f}".format(min_f, max_f, mean_f, median_f)
Results:
Descriptive Statistics: min/max/mean/median (to 1 d.p.)
RM : 3.6 8.4 6.2 6.2
LSTAT : 2.0 38.0 12.9 11.7
PTRATIO : 12.6 22.0 18.5 19.1
Answer:
Recommended price each client should sell his/her home at (based on Predicted Selling Prices):
| Client | Rooms | PovLev | S-T ratio | Predicted SP ($) |
|---|---|---|---|---|
| 1 | 5 | 17 | 15 | 409,395.00 |
| 2 | 4 | 32 | 22 | 195,416.67 |
| 3 | 8 | 3 | 12 | 950,425.00 |
These prices seem reasonable for their respective features because they are in line with intuitive expectations for the given features (per Question 1) and correspond well to the various descriptive statistics calculated for the sample dataset (refer table below).
Client 3’s house (predicted selling price $950,425) has 8 rooms (which is close to the maximum no. of rooms per the sample dataset of 8.4), a student-teacher ratio of 12:1 (in line with sample minimum of 12.6:1) and a very low level of neighbourhood poverty at 3% (sample minimum 2%) . All these features suggest a selling price close to, but slightly less than, the sample dataset’s maximum price of $1,024k. This is also in keeping with our intuition that houses with more rooms, or near to schools with lower student-teacher ratios, or in areas with low poverty levels, will sell for higher prices.
Conversely, client 2’s home (predicted selling price $195,417) has 4 rooms (near to sample minimum of 3.6), a high student-teacher ratio of 22:1 (equaling sample max 22:1) and a high poverty level in the area of 32% (sample max 38%). All these suggest a fairly low selling price, but slightly more than the sample min ($105k).
Client 1’s house (predicted selling price $409,395) has features a little below the sample mean for no. of rooms and S:T ratio, and slightly above the sample mean poverty level. This suggests a selling price close to, but below, the sample mean of $454,343.
Descriptive Statistics for Sample Dataset (Features & Prices):
| Rooms | PovLev | S-T ratio | Price ($) | |
|---|---|---|---|---|
| Min | 3.6 | 2.0 | 12.6 | 105,000 |
| Max | 8.4 | 38.0 | 22.0 | 1,024,800 |
| Mean | 6.2 | 12.9 | 18.5 | 454,343 |
| Median | 6.2 | 11.7 | 19.1 | 438,900 |
(Interesting side note: Copy+Paste from markdown preserves table formatting!)
Model Sensitivity
Although we optimised the model using the above process, there may still be errors of biases or variances within the model, or the chosen model may not have been suitable for the given problem being modelled. Other problems might be caused by too small a sample size, or very ‘noisy’ data (containing lots of outliers and rogue data).
We can define a function (PredictTrials) to run a specified number of trial predictions and compare the results to find the maximum variance between predictions. The function takes inputs of the sample data (features, prices), a fitting model (fit_model) and the new unseen data to perform predictions on (client_data) – note it takes only one client’s data, in this case client 1. It then loops through the specified number of times (iteration variable k), each time splitting the sample data into training and testing data based on a varying random state (random_state = k) and storing the predicted price in a list. Finally it calculates and returns the variance between the max and min predictions.
The function is defined as follows:
def PredictTrials(X, y, fitter, data):
____# Store the predicted prices
____prices = []
____for k in range(10):
________# Split the data
________X_train, X_test, y_train, y_test = train_test_split(X, y, \
____________test_size = 0.2, random_state = k)
________# Fit the data
________reg = fitter(X_train, y_train)
________# Make a prediction
________pred = reg.predict([data[0]])[0]
________prices.append(pred)
________# Result
________print "Trial {}: ${:,.2f}".format(k+1, pred)
____# Display price range
____print "\nRange in prices: ${:,.2f}".format(max(prices) - min(prices))
Call the function using: PredictTrials(features, prices, fit_model, client_data)
(Note: In the project, function is called using vs.PredictTrials(features, prices, fit_model, client_data) since it was stored in separate Python scripts file (visuals.py). This was imported at start of program using import visuals as vs. In order for this to work in Jupyter Notebooks, visuals.py program file was also uploaded into the iPython working space along with the project notebook.)
Results:
Trial 1: $391,183.33
Trial 2: $419,700.00
Trial 3: $415,800.00
Trial 4: $420,622.22
Trial 5: $413,334.78
Trial 6: $411,931.58
Trial 7: $399,663.16
Trial 8: $407,232.00
Trial 9: $351,577.61
Trial 10: $413,700.00
Range in prices: $69,044.61
Question 11 – Applicability of Predictive Model
Required:
Discuss whether the constructed model should or should not be used in a real-world setting, taking account of following questions:
- How relevant today is data that was collected from 1978?
- Are the features present in the data sufficient to describe a home?
- Is the model robust enough to make consistent predictions?
- Would data collected in an urban city like Boston be applicable in a rural city?
Answer:
The 10 trials produce predicted selling prices for client 1’s home ranging from $351,778 to $420,622, with a mean predicted price of $404,474 and range (or variance) in predictions of $69,045. (All monetary values rounded to nearest $.) At 17% of the mean, this variance appears high and suggests the model is not very robust.
The sample dataset, which is from the 1970s, is unlikely to provide a good representation of today’s prices, even despite adjusting for market inflation (which may be inaccurate if applied as an average, hence not equally applicable to all house types and neighbourhoods).
There are also likely to be other factors which account for house prices in addition to the features available in the sample data and used in the model, such as size of garden, neighbourhood crimes rates, access to transport networks and amenities, and so on.
As such, I recommend the model should not be relied upon for advising clients directly on selling prices since it’s accuracy can’t be guaranteed and may result in the agent under-valuing homes by up to c. 17%.
However, it could still prove useful as a general ‘estimating’ tool. For example, to assess which neighbourhoods the agent might target for additional marketing, since they could maximise sales commissions and profitability by targeting neighbourhoods where higher prices were expected.
Project Submission
Date: 24Feb17
See also GitHub repo here: https://github.com/debkr/MLND_boston_housing
Markdown Cheat Sheets:
http://www.statpower.net/Content/310/R%20Stuff/SampleMarkdown.html
https://github.com/bbest/rmarkdown-example
http://english.stackexchange.com/editing-help
https://github.com/adam-p/markdown-here/wiki/Markdown-Cheatsheet
Note: the ‘$’ sign can be rendered in markdown by using ‘\$’, which ‘escapes’ the $, rendering it as a character rather than it indicating the start/end of a formula
References:
Machine Learning Engineer Nanodegree program, Udacity.com