
 Here’s a quick revision and recap on some basic maths and linear algebra needed when studying Machine Learning. This will covers basics of calculus and linear algebra. A future post will revise some basic statistics, then I’ll go on todo some quick example calculations of standard deviations, derivatives and matrix determinants.
Here’s a quick revision and recap on some basic maths and linear algebra needed when studying Machine Learning. This will covers basics of calculus and linear algebra. A future post will revise some basic statistics, then I’ll go on todo some quick example calculations of standard deviations, derivatives and matrix determinants.
1. Linear Algebra – matrix multiplication:
Matrices can basically be though of as arrays of numbers, which might be a simple array (equating to a list in Python) which can be expressed as a simple one-row or one-column matrix:
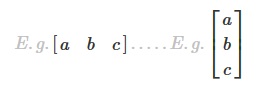 , or they might be more complex matrices with multiple rows or columns:
, or they might be more complex matrices with multiple rows or columns:
 .
.
A matrix can be multiplied by a single number, called a scalar. here, the matrix retains its shape (rows and columns) and each element within the matrix is muliplied by the scalar to give the new, scaled matrix.
Things get more complex when we want to multiply two matrices together. Here we use the Dot Product function which multiples rows and columns in a particular order. Here’s an example:

Matrix A (2 rows, 3 columns) is multiplied by Matrix B (3 rows, 2 columns) to give Matrix C (2 rows, 2 columns). First take A:row1 and multiply each element by its counterpart in B:column1 and add the products together, giving the value ‘w’. Repeat the dot product process with A:row1 and B:column2, giving ‘x’:
![]() and
and ![]() .
.
Repeat the dot product calculation using A:row2 with, first B:column1, then with B:column2, to give ‘y’ and ‘z’ respectively:
![]() and
and ![]() .
.
From the example it can be seen that, in order to complete the matrix multiplication, it is necessary that the number of columns in the first matrix (A) equals the number of rows in the second matrix (B), and that the resulting matrix (C) will consist of the same number of rows as in A and the same number of columns as in B.
A simple example of the use of matrix multiplication would be where there are sales of multiple products taking place on multiple days: to calculate the total sales on each day, we would sum all the products of each day’s sales quantity x each product’s selling price. For example, given sales over 5 days for 3 products, the resultant matrix shows total sales revenue for each of the 5 days:
 .
.
2. Calculus – basic differentiation:
Basic calculus (differentiation and integration) skills are important and often used in machine learning algorithms. We’ll often model a problem based on a function (the prediction) and then try to optimise that function by looking for the point at which the error between the prediction and actual results is at a minimum. We can do this by taking the derivative of the prediction function and solving it for a minimum (i.e. solving for that point at which the gradient of the derivative is zero, which equates to the point where the error between predicted and actual results are minimised). Conversely, we would solve a derivative for a maximum, which would equate to the optimisation of a function to the positive (e.g. where we are looking to optimise sales). More on this can be found in my earlier post revising Simple Linear Regression.
In the meantime, here’s a very basic recap of simple differentiation. The basic process
xx
Some Rules of Differentiation:
1. For a constant function f(x) = n, where n is a constant real number, its derivative wrt x is zero: ![]() ;
;
2. For a linear function f(x) = mx + n, where m and n are constant real numbers, its derivative wrt x is: ![]() ;
;
3. The Power Rule states that, for some function f(x) = ax^n + b, where a, b and n are constant real numbers, its derivative wrt x is: ![]() . This rules holds in the special case where n = 1, resulting in the rule we see for linear functions (rule 2 above). It also holds where n is a fraction (i.e. the nth root of x) or a negative number (i.e. x divided by n).
. This rules holds in the special case where n = 1, resulting in the rule we see for linear functions (rule 2 above). It also holds where n is a fraction (i.e. the nth root of x) or a negative number (i.e. x divided by n).
4. The Addition and Subtraction Rule states that, where a function f(x) consists of various elements which can be split out into separate functions, e.g. f(x) = g(x) + h(x) or f(x) = g(x) – h(x), the derivative of f(x) wrt x is equal to the addition or subtraction of the derivatives of the individual functions wrt x. That is: ![]() ;
;
5. The Product Rule allows for the differentiation of a function which is a product of two other functions. For example, given function f(x) = g(x).h(x), its derivative wrt x is the sum of (the product of the derivative of g(x) and h(x)) and (the product of g(x) and the derivativ of h(x)), which can be stated formally as: ![]() ;
;
6. The derivative of function f(x) = e^x equals e^x (that is: ![]() ).
).
Read more like this:
This post is part of an ongoing series where I get to grips with mathematical skills for artificial intelligence. There’s various branches of AI, but here I’ll be focussing on those I’m most interested in: machine learning, neural networks, natural language processing.
I’ll be recording my own self-guided learnings (part of the Mathematics Stream of my Personalised Training Plan – you can see the summary syllabus here), as well as responses to and learnings from various MOOCs and online courses I’m studying.