
 Starting out with databases:
Starting out with databases:This section moves on to working with SQL databases (focussing on SQLite3) as well as delving into some data gathering, analysis and visualisation in Python. Why store the data? Well we probably want to build up data over time – maybe it’s coming from reviews of customer activity, or PR hits, or perhaps we’re scraping data from the web and the web crawler is continually replenishing its list of target URLs (hence going crawling some more). Or maybe we’re getting our data from an API which restricts our access on a rate-limiting basis so we can only run x queries today, then have to wait a while before we can make more requests.
In all these cases, we’re going to want to store that data in the most convenient and accessible format. It also helps that we can retrieve, clean, store data as a separate activity from our analysis and visualisation/reporting of the data. This gives us both more flexibility and greater speed of processing.
In this course we focus on learning and using SQLite with Python. There’s plenty of documentation on this over at Python.org, but it also benefits from having a handy open-source browser (http://sqlitebrowser.org/) which means that not just Python can read the data stored there but we can too.
SQL and relational databases:
SQL stands for Structured Query Language which is a programming language designed specifically for managing data that’s held in a relational database. Which begs the question, ‘what is a relational database?’ This is a data management system where the data has been organised in tables (or rows and columns, a little like a spreadsheet), but where the relationships between the items of pieces of data held within the database hold some kind of relationship with one or more other pieces of data in the same database. This set of relationships is what defines the data structure. SQL is the specialist programming language which is used to query this data, and it’s underlying relationships.
One simple way to think of how this data structure differs from earlier, less advanced types, is that previously data could be through of as stored in analogue or series fashion. It might be a file which consists of lots of lines of data – whether that be a text file, or whether organised in more structured ways in trees, or maybe on a magnetic tape. In all these cases, the file or tape had to be read in from start to finish and the relevant item(s) you require searched for and extracted. This works fine for small files or small amounts of data. But for larger datasets (even those generated by a small enterprise) would be too large to be handled efficiently this way – especially if that data is being amended or replenished daily.
By using a relational database to store the data, savings can be made in both time of processing/querying and in storage file size. By storing data in a number of different tables and building links between those data tables (hence by default between the data elements within those tables) we drastically cut down the time taken to upload/amend or query/report on that data. This is because not all data will need to be processed through the CPU at any given time for any given task (we don’t need to run through the data sequentially, but can just dip in and out to the relevant bit we’re interested in).
You can think of this simplistically as the data being structured like a set of lights wired in parallel rather than in series – electricity need only pass down one part of the wires, to light those bulbs we require to be lit, while all other lights remain unlit.
Structure of a relational database:
Database: the whole dataset, consisting of tables of data.
Relation (Table): a data-holding structure made up of columns and rows (equivalent to a spreadsheet).
Tuple (Row): a row of data in the table relating to one object or record; a row consists of a set of fields.
Attribute (Field): the columns within the table which correspond with the data in the row/object/record.
In technical terms, a relation is a set of tuples containing some attributes. We should think of the tuple as being the object and some information/meta-data about that object (its attributes, etc.). Remember when we looked at tuples in Python, we saw they were sets of multiple elements, and we can think of the tuple (row) in the database in the same way: it’s a set of data points which are grouped together as one object or set.
Attributes are the pieces of information or meta-data about the specific data elements with the tuple/object/set – like the columns headers in a spreadsheet. The structure of the database is laid out according to those attributes (column headers) and is referred to as the database schema. Schema (like we saw with XML) includes not just what the data-points represent but also what format they can appear as (string, integer float, etc.), order, data length, whether mandatory or optional, and so on.
SQL database as an abstraction:
Abstraction in computing terms refers to keeping one part hived off and separate – in this case, de-integrating the database or data storage element – and the software which understands it – from the main CPU, hard drive storage and our application from which we’re performing the various data extraction/manipulation/reporting tasks.
It’s like keeping all the difficult and complex bits hidden inside a box so we don’t really need to see or worry ourselves about what’s going on, which makes our job of writing applications to perform various tasks that much easier. This is another example of the Service Oriented Approach and APIs that we learnt about in part 12 covering data extraction with JSON.
SQL as a protocol; SQL limitations:
In order for database abstraction to be successful there needed to be some standards and protocols around how to structure the data and how to query it. The standard developed is what became the SQL language, and it can be used across a variety of different databases from different software providers.
SQL is a very simple, expressive and elegant language, and SQL databases are built in a highly optimised format which allows for rapid storage and retrieval of data. That makes them really powerful (and fast – even for relatively large datasets).
It does have a drawback though, and that is its dependence on the data (for storage/querying) being well-structured (hence the name!). So it’s not as useful or flexible for random and chaotic sources of data as we might find from scraping the web. Python wins out in the flexibility stakes there.
But if we can scrape then transform our data into a structured format (and Python, as we’ve seen from our various experiments playing around with raw data, is great at doing this), we can store it in a structured relational database, then easily use SQL for ongoing querying/analysis/reporting – particularly where we know the ongoing need is there (same or similar queries and reports required daily/weekly/monthly/annually, as is so often the case in business uses).
Providers of relational databases:
There are various relational database providers of which the key industry players include:
- Oracle (top-flight, enterprise level)
- MySQL (simple, fast and scalable, now owned by Oracle)
- MariaDB (an exact copy of MySQL from its original developers, free and open-source, available from https://mariadb.org/)
- Microsoft SQLServer (and to a lesser extent MS Access)
There’s also a wide variety of smaller, free and open-source databases including SQLite, HSQL, Postgress (built similar to Oracle DB) and more. MySQL tends to be the preferred choice for online and web-based database solutions. SQLite which we use here is known as an embedded database, i.e. it sits within some other software as a part of it. There’s lots of different companies and applications that have it built in – including Python (we just need to import the relevant library).
Elements of building and maintaining a database:
- Defining the logic of the database (together with its underlying data structure and schema) as well as determining what data should be stored in it;
- Designing the look and feel of the database (including building various application software: appropriate and accessible user browser interfaces, data analysis dashboards, regular report suites, ad hoc query and reporting interfaces, etc.);
- Maintaining the technical and security aspects of the database;
- Maintaining the database on an ongoing basis, ensuring accuracy and integrity of data stored within it and reports being run from it (including maintaining regular and ad hoc reports through use of database tools).
Analysing data with Python and SQL:
Our data analysis set up (when working on a small scale) is likely to be:
1. Input data files or network connections (e.g. scraped from websites, or retrieved from the web using APIs)
2. Develop Python programs to retrieve, read, clean and manipulate input data
3. Develop Python programs to transform and write cleaned data to SQL database for permanent storage (this step requires that the first item on previous list has been completed, i.e. defining database logic/data structure/schema)
4. Monitor and maintain data integrity and data structure using database tools (e.g. SQLite browser)
5. Query and retrieve data from SQL database using Python, and prepare data in a format suitable for output
6. Output formatted data to other data analysis tools (e.g. Excel for simple analysis, presentation and sharing, R for complex statistical analysis)
7. Ditto visualisation tools (e.g. D3.js)
8. More advanced users will be able to take outputted data into machine learning/deep learning algorithms within either/both Python and/or R (using relevant packages/libraries) – this step is beyond the scope of this introductory coding series
Building a simple single-table database with SQLite:
The simplest way we have of creating a new SQL database, formatting it as required (tables, fields, etc.), and reading and writing data to it, is using a database tool like SQLite (download links above). SQLite has a really simple and intuitive screen which you can experiment with by setting up a test database and just playing around.
Here are some beginning guidelines:
1. Establish the data model or data structure first – i.e. setting the Database Schema: what data do you want, what format will it be in, what field length each field will be, how are you going to use the data, etc. When setting up a simple single-table database (equivalent to an Excel spreadsheet of columns, column headers and data rows) this will be easy – but we still need to think about the type and format/length of the fields we’ll be setting up.
2. Open up SQLite. Click on NEW DATABASE and choose name and location to save the new database file.
3. Either start creating a database table now using the pop-up dialogue box, or click cancel and click on EXECUTE SQL instead to bring up the SQL pane where you can code SQL directly. Harder than using a wizard, but really not hard at all at this simple stage.
4. To create a simple table with two fields, in the EXECUTE SQL pane type:
CREATE TABLE Tablename(
fieldname1 VARCHAR(128),
fieldname2 VARCHAR(128)
)
Create fields in the table as a bracketed list, with each field separated by commas, specifying name, field-type and field-length (e.g. alpha of no more than 128 characters).
Execute the SQL you’ve typed into the pane by clicking the Execute (‘play’) button.
5. View the structure / schema of the database at any time by clicking on BROWSE DATA and referring to the viewing pane at right-hand side (click on the expand/contract arrows by a table or field name to expand or collapse the list as required).
The Database Schema viewing pane includes table/field names, their types/lengths and the DB Schema (widen or narrow the column widths as you would in Excel to get all the columns to fit in the pane).
6. Enter data into the table using the BROWSE DATA tab. Click on NEW RECORD – a new empty data row will be created, containing NULL as a default. Note: new records are always added at the end of the list. Type data into the relevant fields in the left-hand pane. Editing a data value is simple: just click into the field and edit or over-type. To delete a record, simply highlight and click DELETE RECORD.
Resize the columns as they appear on the screen just as you would in Excel – either by clicking and dragging, or by double-clicking to dynamically resize. Data fields can be sorted ascending or descending by clicking on the field header.
7. Another way to insert a new record into the table – rather than using NEW RECORD in the BROWSE DATA tab – is to execute an SQL command in the EXECUTE SQL tab. Click on EXECUTE SQL, clear out any previously-executed commands from the pane, then type:
INSERT INTO Tablename (fieldname1, fieldname2) VALUES (‘value1’, ‘value2’)
Hit the EXECUTE button and the listed values ‘value1’ and ‘value2’ will be inserted into the listed fields filedname1 and fieldname2 respectively in the Tablename table.
8. Similarly you can delete a record or data row from the table using an SQL command in the EXECUTE SQL tab instead of the DELETE RECORD button in BROWSE DATA tab. Here you can specify a deletion criteria (i.e. IF some criteria is met, DELETE that record). Click on EXECUTE SQL, clear out any previously-executed commands from the pane, then type:
DELETE FROM Tablename WHERE fieldname1=’value’
Hit the EXECUTE button and the data row / record which contains the specified value in the specified fieldname in Tablename will be deleted. Using WHERE followed by a condition ensures that only those records are deleted for which the logical statement (selection criteria) is True.
9. Editing a record can also be done with SQL code instead of by browsing/editing the data. Click on EXECUTE SQL, clear out any previously-executed commands from the pane, then type:
UPDATE Tablename SET fieldname1=’value1′ WHERE fieldname2=’value2′
Hit the EXECUTE button and the specified fieldname will be edited in the data row(s) where the specified selection criteria is met.
10. We can also retrieve data from the database, using various selection criteria, using the SQL command SELECT. Again, this is executed in the EXECUTE SQL pane as before. Type (then hit the EXECUTE button) one or other of the following:
SELECT * FROM Tablename
SELECT * FROM Tablename WHERE fieldname1=’value’
The first command selects all (indicated by the wildcard *) the records from the table called Tablename. The second command selects all those records from that table which meet the specified criteria. In both instances, the selected records will appear in the bottom left-hand pane on the EXECUTE SQL tab.
11. Sorting can be done in SQL code by updating the SELECT command to add a sorting criteria. For example:
SELECT * FROM Tablename ORDER BY fieldname1
SELECT * FROM Tablename WHERE fieldname1=’value’ ORDER BY fieldname2
12. Selects and sorts can be performed with multiple selection criteria using Boolean Operators (AND, OR, NOT, AND NOT). For example:
SELECT * FROM Tablename WHERE fieldname1=’value1′ OR fieldname1=’value2′ ORDER BY fieldname2
13. To return the count of records in a given table, use the basic command below (either as is, or modified with WHERE + selection criteria):
SELECT COUNT(*) FROM Tablename
Some notes on successful use of SQLite:
- Only read and write code or data to this file with this tool, rather than accessing file / writing code directly. Click on SQL LOG at bottom of right-hand pane to see the SQL raw code being written;
- Use UPPERCASE when writing SQL commands as SQL is case-sensitive (barring a few minor exceptions);
- Indentations don’t matter to SQL when creating fields in a table, but they do aid human readability;
- Top tip: if it confuses you, ignore the SQL LOG tab. But it’s a good place to watch and see what happens in the underlying SQL as you execute some command, browse some pane, etc.. That makes it a good place to learn if you like diving in deep.
Reading external data into an SQL database using Python:
Because SQL comes as a built-in library to Python, we’re able to read and write data from either a file or a web page just like we learnt before, but this time (provided we can get the data into the required data format) write it directly into a previously-created SQL database.
To do this we first need to (1) import the SQL library, (2) create a connection to the relevant SQL database file (e.g. ‘dbname.db’ or ‘dbname.sqlite’, where extension .db or .sqlite denote a database created in SQLite browser – note the database filename does not already need to exist, the command will create one if not already there), and (3) create a means by which we can send instructions to execute SQL commands on the database – referred to as a ‘cursor’.
These three lines of Python code look like this:
import sqlite3
connection = sqlite3.connect('dbname.db')
curs = connection.cursor()
It’s good practice, once a new file has been created and table(s) set up, to commit (save) the data changes to file using:
connection.commit()Once we’ve established the connection and the cursor, we can start running SQL commands on the specified database file, in exactly the same way we did in the EXECUTE SQL pane of the SQLite browser. So to create a new table, we’ll use the Python code:
curs.execute('''CREATE TABLE Counts (email TEXT, count INTEGER)''')
If we were using this as a test database and/or wanted to be sure it was an empty database before we begin writing data to it, we can use a DROP command to clear/delete the specified table from the database file before we begin, using the following:
curs.execute('''DROP TABLE IF EXISTS Counts''')Note the SQL command is contained within the execute() function (which resides in Python as part of the imported SQL library) as a triple-quoted string, similar to how we denoted XML and JSON strings. The example shown creates a table called Counts containing two fields, one a text field and the other an integer numeric field.
We can now access our data source (text file or web page, using imported urllib for the latter) in the normal way by looping through the lines in the file/web page and searching for/extracting the relevant data (e.g. email addresses).
We can do several things with the data we’re interested in (the following examples look at a simple database counting the number of times an email appears in the data source):
a. SELECT data from the database. For example, check if the email address found in the data source is already in the database, and return the count value currently stored in the database for that email:
curs.execute('SELECT count FROM Counts WHERE email = ? ', (email, ))
datarow = curs.fetchone()
The first line of Python code above executes an SQL command to select all records in the Counts table for which the value in the email field is equal to a placeholder value (denoted by ‘?’). The placeholder value is taken from the tuple variable (email, ). Here we only need one value from the tuple to be entered into the placeholder ‘?’, i.e. the first value in the tuple: ’email’, but we need to show the tuple in its full format, i.e. (value1, {empty, indicating ‘no second value’}). On executing the SQL command, the value currently stored in the count field for this email address is returned. (Note we specified that only the values in the count field be returned, not the whole data row.)
The second line of code fetches the data returned by the previous select; in this case it returns the value in the count field only. It returns the data either as None (the email is not found in the current database) or in the form of a tuple of one value e.g. (1, ), (3, ), etc. indicating the count value currently stored in the database.
b. WRITE data to the database. For example, use a conditional to check the status of ‘datarow’ as either None or some value, and execute the relevant SQL command accordingly. If None, we want to add the email address to the database for the first time and set the count value to 1. If not None, we want to update the count value to increment it by one:
if datarow is None :
curs.execute('''INSERT INTO Counts (email, count) VALUES ( ?, 1 )''', ( email, ) )
else :
curs.execute('UPDATE Counts SET count=count+1 WHERE email = ?', (email, ))
When all data has been written to the database file, the data changes should be committed (saved) to file using:
connection.commit()
c. QUERY data stored in the database. For example, use and SQL SELECT to select data for a required search/sort criteria, then use a for..in loop to iterate through all records returned and print out the results:
for record in curs.execute('SELECT email, count FROM Counts ORDER BY count DESC LIMIT 10') :
print str(record[0]), record[1]
In the above example, sort is ordered by descending values, and a limit for returning/printing out has been specified to maximum 10. In other words, return the top ten values. The limit command is valuable if you have a very large database.
The str() function is useful for converting any values into a string (true alpha-numerics) in the event there were any UTF-8 codes being read from the file. Such characters, Python would normally render as UTF-8 (gobbledegook) on printing or appending to a list or writing to a database, etc.. Using str() ensures the true character gets returned not the UTF-8 code. (Note: this is not the same problem as I was finding during the HTML reading/tagging exercises. These are due to the HTML encoding of the source web data. Read more about HTML character encoding on Wikipedia which may give a steer as to how to fix that particular problem.)
Once all selecting/writing/querying from/to the database has been completed, the link to the database (‘cursor’) should be closed using:
curs.close()
Ideas and extensions:
Just from this very quick and dirty intro to simple SQL with Python, I can see how valuable this would be for re-building the keyword tagger (used for finding top keywords in an article or blog post). If this were re-worked into an SQL database, the data would not need to be written to a series of different files (each named for the individual blog title) but could instead be saved into an SQL tagging database. This would (a) speed up processing/calculating of the top-n keywords/tags, and (b) hold the keywords on file for later use. This second benefit will really come to the fore as I develop the tagging engine further into a knowledge-base (for use in various stretch projects, ultimately aiming towards building a bot or intelligent agent as a personalised learning/training agent).
Database applications:
There’s so many ways we can use even a simple SQL database, either as a stand-alone database or as part of a website or application used to track/display data. For example, a book collection, a recipe database, a fitness app, or even just a simple one-table contacts database. But why not just keep that on an Excel spreadsheet instead? In some case, we could. But as the world gets more connected, so must we if we want to keep in the loop.
So even if we use only a simple database, by adding in Python into the mix we’ve got ourselves a very fast combo for retrieving data from elsewhere and uploading it into a structured database – and subsequently querying, extracting, transforming and updating that data – while all the time allowing us full accessibility and connectivity to the ‘net.
Moving onto multi-table relational databases:
Where SQL really comes into its own though – particularly in business settings – is when there are multiple tables, with lots of relationships and links between multiple data points across multiple tables. Storing, retrieving and querying such a complex relational dataset in SQL is really powerful and flexible.
With that complexity comes an even greater need for good intelligent design before the fact, making Step 1. of our Beginning Guidelines above even more important. The best way to do so if to have a clear picture of what the database needs to do (what is the data it will be storing, and the connections between that data) – this can often comes in the first instance in the form of process maps or flow-charts for the enterprise or application. These come from asking wide-ranging and general questions about the enterprise or application (“What happens during the process to create/use/destroy the data?” “What are the different classes of data we’ll need to deal with?” “What are we using that data for?”). And with each pass, narrowing down from top-level overview down to granular detailed view.
Once we have this background information mapped out, we can then go on to formalise in terms of a relational database. This consists of mapping out all the tables needed in the database (the classes of information we’ll need), all the attributes of fields within each table (together with their data types and any other relevant meta-data such as mandatory/optional, data type and length, etc.), and how all the data tables fit together (coming from the process flows mapped out above). All of these design elements together will make up the Database Schema.
Getting relational:
The way all the various tables fit together – the relationships between them – is the ‘relational’ part of relational databases. When building a multi-table database, additional columns are added to indicate what relationships (if any) that table holds with other table(s) in the database.
Possible relationships between tables are expressed in a variety of ways:
- Non-related:
- The table is not related to any other table in the database (e.g. static historical sales order data or historical customer attributes data – uploaded from an old database into a static history table in a new database in order to preserve data/reporting continuity and provide deeper querying functionality);
- One-to-many:
- The table exists as a data look-up table which feeds into one or more other tables (e.g. payment type table holds details of all the payment types a company will accept on a sales order – one payment type can exist in many sales orders);
- The table exists as a repository of a key data class (e.g. customer table – there are many individual customer records but only one customer record for each individual customer [assuming you’re not creating duplicates!] but each individual customer may have placed many sales orders) (e.g. product table – there are many unique products, and each one may be held in multiple warehouses, and ordered/despatched against multiple sales orders);
- Many-to-one:
- Inverse of the one-to-many relationship (e.g. many sales orders can be placed by one customer, many items can be bought in one order, etc.);
- One-to-one:
- The table holds unique data about a unique data point in another table (e.g. customer delivery address may exist as a separate table from the customer table, but where each customer can only have one delivery address set [in practice, if this were the case, it would be better to include within the customer table; alternatively if multiple delivery addresses were allowed per customer, this would become a many-to-one relationship];
- Many-to-many:
- A complex data class, often the core data class of the enterprise or application, occurring across multiple instances throughout (e.g. one product purchased in multiple orders, and an order may contain more than one of the product [in practice this would better be handled as a quantity identifier to the product line within the order table];
- Self-referencing:
- A table which references itself (e.g. when tracking a customer referral program).
In simple terms, if you’ve got lots of data fields and you’ve organised them into sensible tables (or types/classes of data), then where the same data field appears in multiple tables gives you the steer towards the relationship(s). You don’t need to keep repeating that data field (customer, product, etc.) in lots of tables, you just hold it in one (generally) source table, then create relationships from that source table through to all the other tables that data field touches. A good rule of thumb from Dr Chuck’s course is: if it appears once in the real world, it should only appear once in your database. This allows the database to be modelled on the data connections, which is what gives it the desired power and flexibility.
Designing a data model:
Goal: To build an intelligent database which is fast to populate, maintain and query [suggests using numbers to represent data and links], but which can also be presented to end-users in a clear readable and easily-understood way [suggests using words and long descriptive strings].
Things to consider: Start with the data; ask whether it’s an object (a piece of hard data in itself) or an attribute of some other object or piece of data; then build the relationships between the various data objects.
Where to begin: Best practice is to begin with the data object most essential to the process or application for which the database is being built (e.g. in a recipes database, begin with recipe; in a customer relationship management database, begin with customer; in a stock control database, begin with product line or SKU/stock-keeping unit). Of course, in larger enterprise-level uses there will probably be lots of different functions/applications needing to be addressed by one integrated database (think ERP/business system) – here perhaps it’s best to chunk each section down and work on it in isolation, but being sure to keep the overview of how all the different chunks fit together and talk to one another across the whole db.
Example (data model for an easy multi-table recipe database):
The database will contain a number of different recipes. Each recipe is a data record, consisting of data like preparation time, cooking time, number of servings, ingredients and their amounts, and instructions to make and cook. Of these, things like the prep time, cooking time, number of servings, instructions and so on, are simply attributes of the recipe.
The type of recipe is not an attribute of one recipe, since many recipes in the database might be desserts, or main courses or starters, and so on. So we create a separate table for recipe type, and link it to the recipes table.
There are lots of possible ingredients we might cook with, and each one can appear in any number of recipes, so ingredients should be constructed as a separate table. Each recipe can contain many ingredients, so we should create another table to list all the recipe ingredients contained in a given recipe – this will link to ingredients on the one hand and to recipe on the other.
However, the amounts of ingredients being used in a given recipe can be considered attributes of the ingredients data rather than separate data itself (unless you wanted to go for greater complexity and add units as a data look-up table to assist with data entry – doing so would speed things up if the database were expected to be very big).
Table: Recipes [highest-level data class]
Fields: RecipeName; RecipeTitle; {recipe type}; RecipeDescription; PrepTime; CookTime; Servings; {recipe ingredients}; PrepInstruction; CookInstruction
Relationship: MANY {recipe ingredients} belong to ONE {recipe}
Table: RecipeIngredients
Fields: {recipe}; {ingredient}; Amount; Unit; Notes
Relationship: ONE {ingredient} belongs to ONE {recipe ingredient}
Relationship: ONE {recipe} belongs to MANY {recipe ingredients}
Table: Ingredients
Fields: Ingredient; Notes
Relationship: ONE {ingredient} belongs to ONE {recipe ingredient}
Table: RecipeType [lowest-level data class]
Fields: RecipeType; Notes
Relationship: MANY {recipes} belong to ONE {recipe type}
Building the data model into tables:
To build the model into a relational database, we take the table with its column headers (fields or attributes) and to this, at the beginning/first column, we add a primary key field (a unique auto-generated ID number), and at the end we add any fields required to map the various relationships of this table to other tables in the database. This link is made by creating a foreign key which points to the primary key (ID number) in the target database, and setting the relationship type as required (one-one, one-many, etc.).
We also have the option to define one of the fields in the table as the logical key; this acts as an alternative look-up value which may be used by external users to query data in this database. In our recipe database example we would most likely choose Recipe Title as the logical key since this would be the term end users would be most likely to search on. Each table can have a designated logical key, so for example the ingredients table we would likely want to set the logical key as Ingredient so users can search on that and find all recipes in the database that ingredient features in, and so on. Setting a logical key for a table is optional, but it builds in capability in how the data gets structured and stored which optimises the database’s query-ability (i.e. it’s a field likely to be used as search criteria in an SQL command using WHERE or ORDER BY).
So converting our list of tables and fields above (and rationalising/shortening table and field names as we go) gives us:
Table: Recipe [primary data class]
Fields: id [Primary Key]; title [Logical Key]; type_id [Foreign Key; only ONE per record]; descr; prt; ckt; serv; prins; ckins; note
Table: RecIngr
Fields: id [Primary Key]; recipe_id [Foreign Key; MANY records may map back to ONE recipe]; ingr_id [Foreign Key; only ONE per record]; amnt; unit; note
Table: Ingr
Fields: id [Primary Key]; ingr [Logical Key]; note
Table: Type
Fields: id [Primary Key]; type [Logical Key]; note
Setting up the database:
In SQLite Browser it’s really quick and easy to set up these tables and fields, especially if you use the Create Table wizard (Click NEW DATABASE and name/save it, then select Menu\Edit\Create Table). The wizard is very intuitive and helps to quickly define the required schema. Handily, the SQL code is also replicated in the bottom pane as you go along.
The convention for setting up the database is to start with the simplest/lowest-level tables first (those which don’t contain foreign keys) and work upwards towards the most complex/high-level table(s) (containing the most foreign keys). Here’s the code to set up the Table: Type (to store the recipe types, main course, dessert, etc.):
CREATE TABLE `Type` (
`id` INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT,
`type` TEXT,
`note` TEXT
)
The new SQL code is the second line which sets up the ID field as an integer, specifies it as mandatory (NOT NULL), as the Primary Key, and sets it to automatically increment by 1 for each new record added to the table.
The alternative to using the Create Table wizard is to revert to the SQL coding pane (click EXECUTE SQL), copy/edit the above SQL code for the next table, and hit the EXECUTE button. To set up Table: Ingr (ingredients), the SQL code will be the same as above, with only the table name and second field name changing.
Next up is to create the Table: RecIngr (recipe ingredients). Most fields here as as before, but we also need to set up a Foreign Key field called ingr_id. We set this as an INTEGER for now, since this maps to the INTEGER value id in the Ingr table. The SQL code looks like this:
CREATE TABLE `RecIngr` (
`id` INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT,
`recipe_id` INTEGER,
`ingr_id` INTEGER,
`amnt` INTEGER,
`unit` TEXT,
`note` TEXT
)
We could make the database more advanced by restricting the string length for Units (or better yet, call it from a data look-up table) and set the Amnt field to allow alpha-numeric entries. But we’ll just keep things straight-forward for now. We do a similar thing to set up Table: Recipe, but here there are two Foreign Keys (type_id and recingr_id), both of which are set to INTEGER.
Populating the database:
As with setting up tables, so with populating with data, the convention is to start with the lowest level tables first. This makes sense, since we can’t add the relevant integer id for Recipe Type: Starter to the type_id foreign key in Table: Recipe until we’ve added it to Table: Type. SQL code for inserting values into tables looks like this (multiple data rows can be added at the same time, as long as each line separated with a semi-colon):
INSERT INTO Type (type) VALUES ('Basics') ;
INSERT INTO Ingr (ingr) VALUES ('Flour, plain')
When we want to add a data row which has multiple fields, we need to specify all the field names, separated by commas, in the first brackets, then all of the values, again separated by commas, in the second brackets. To populate data for foreign keys, the simplest way (in a small, simple database such as this one) is to use the relevant integer to represent the ID number in the source table, e.g.:
INSERT INTO Recipe (title, type_id, prt, ckt, serv, recingr_id)
VALUES ('Rich Sweet Pastry', 1, 20, 15, 6, 1) ;
In practice, we’d most likely be entering data via a program or a user interface, either of which would do the relevant foreign key data look-ups for us.
Reconstructing data with JOIN:
For even a modestly large database, especially where there are a links between quite a few data values from different tables, the use of foreign keys becomes critical to ensure minimal storage size and optimal querying speed. And its importance grows as the database scales – which is likely with an enterprise application – so better to fix the relational aspect right from the start. Integer values are far easier for computers to store, index and query than strings are. So, at scale, by ensure any string data replications are coded into integers (not left as strings) when storing in the database, makes it easier for the computer to handle.
But this is not so readable or friendly for us human users. So we make use of the SQL operation called JOIN .. ON. This allows us to link data across multiple tables, by specifying what is the type of relationship of the join and select/return the underlying source data (the original string) not the integer id value. This is why it’s referred to as ‘reconstructing’ the data, i.e. putting it back into human-readable format.
The basic syntax of the JOIN operation is: SELECT {values to be returned} FROM {first table} JOIN {second table} ON {how the two tables are linked together}. An example from the above database demonstrates how this works:
SELECT Recipe.title, Type.type FROM Recipe JOIN Type ON Recipe.type_id = Type.id
This returns a list of all the recipe titles and their recipe types. Here the ON clause is acting exactly as a WHERE clause (search criteria) did in previous examples.
This doesn’t just work for a one-to-one data link; we can also use JOIN to select where there are multiple records in one table associated with one record in another table (e.g. all the ingredients in a recipe):
SELECT Recipe.title, RecIngr.ingr_id, RecIngr.amnt, RecIngr.unit
FROM RecIngr JOIN Recipe ON RecIngr.recipe_id = Recipe.id
This is flawed, though, since Table: RecIngr also has a foreign key linking to the id number in Table: Ingr. The above select just returns the primary key id number from that table, whereas we want to see the ingredient itself. Firstly, to see a list of all ingredients and their attributed (ignoring recipe), we would use:
SELECT Ingr.ingr, RecIngr.amnt, RecIngr.unit FROM RecIngr
JOIN Ingr ON RecIngr.ingr_id = Ingr.id
What we want to achieve is a double-join, i.e. join Table: RecIngr with Table: Ingr to retrieve the ingredient field, and then to join Table: RecIngr with Table: Recipe to retrieve the full list of ingredients by recipe title. We can achieve this by nesting the JOINS as follows:
SELECT Recipe.title, Ingr.ingr, RecIngr.amnt, RecIngr.unit FROM
(RecIngr JOIN Ingr ON RecIngr.ingr_id = Ingr.id)
JOIN Recipe ON RecIngr.recipe_id = Recipe.id
Here’s a screenshot of what this select query returns:
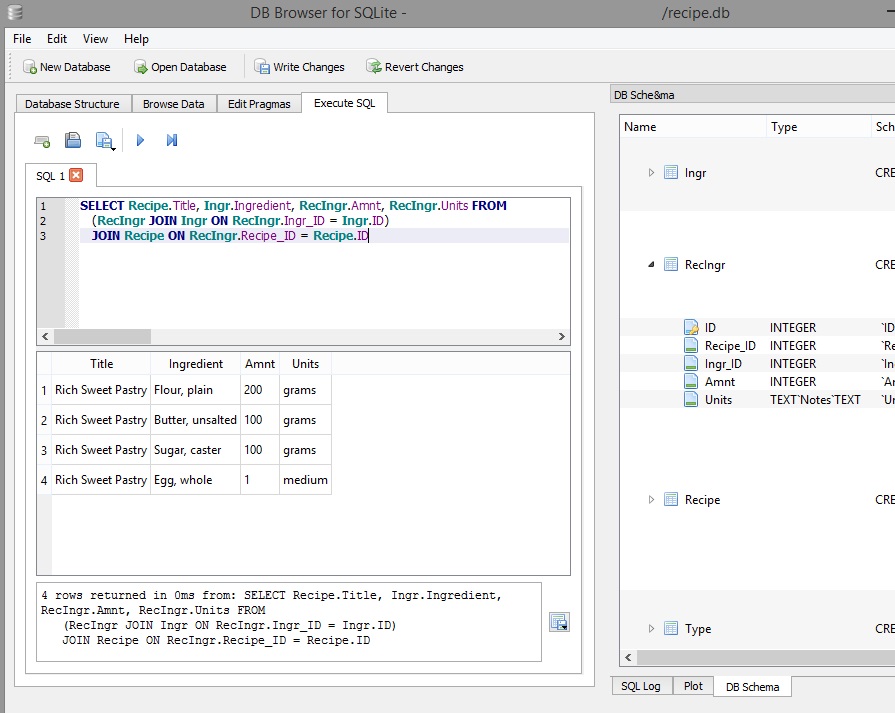
There’s also another way of rendering that complex multi-table select. We simple join together all the tables we need to query using syntax like this: FROM {table1} JOIN {table2} JOIN {table3} ON {first criteria, tables 1 & 2} AND {second criteria, tables 2 & 3}. The same query (recipe + ingredients/amounts/units) using this alternate syntax looks like this:
SELECT Recipe.title, Ingr.ingr, RecIngr.amnt, RecIngr.Uuit
FROM RecIngr JOIN Ingr JOIN Recipe
ON RecIngr.recipe_id = Recipe.id AND RecIngr.Iigr_id = Ingr.id
We also have the option of adding sort criteria to our JOIN queries as well, giving us even greater flexibility. But I won’t cover that right now as I want to wrap this post up for today.
Wrapping up and notes on presentation:
Before I go, just a few notes on presentational conventions. We saw at the start that generally SQL syntax is not case sensitive for the reserved words (SELECT, JOIN, ON, etc.) but common sense and good style suggests we should stick with one case convention throughout. Case does matter with table names and field names though. But this seems to be personal preference: some use all lower case, some take a mix of lower and upper. My own preference, learned way back when designing and building MS Access databases, is to use capitalised case to help with understand-ability of the names I’ve used.
Another point to note is when typing SQL code: we saw in a few examples above that we can execute multiple lines of SQL together, they simply need to be separated by a semi-colon. We also saw how some selects/joins (especially when using nested joins to access data across multiple tables) can lead to a very long line of code. We are able to wrap that onto several lines – SQL will just ignore the extra whitespace – and only stop reading that line once it reaches the semi-colon. (But remember, there’s no semi-colon required at the end of the final line of code.)
Read more like this:
This post follows on from earlier Coding 101 posts and records my responses and learnings from the highly-recommended Python programming book and Coursera specialisation by Charles Severance (see References below).
References:
Book: Programming for Informatics – Exploring Information by Charles Severance
Course: Using Databases with Python by Univ. of Michigan. Part of the Python for Everybody specialisation.